There are many forums in the past couple of years where I have talked about how non-code contributions are just as important to MariaDB Server and us at the MariaDB Foundation as the code contributions I typically help with. I’ve also highlighted in the past how Intel have provided some fantastic non-code contributions. They assist us by detecting performance issues on their new and future platforms, as well guidance in finding the root cause of these issues.
The outcome: Over a million NOPM in HammerDB
Today I want to discuss some of the performance improvements that Intel has helped with, which have led to MariaDB Server achieving 1 million NOPM (new orders per minute) in the HammerDB TPROC-C test. This was only possible thanks to tickets filed by Intel such as MDEV-33515 (log_sys.lsn_lock causes excessive context switching) and related pull request by Marko from the InnoDB team.
Before I delve into the details, I also want to thank Marko Mäkelä for being a great open source citizen here for crediting Steve Shaw from Intel with the discovery in the commit message.
The problem: Lock contention – platform dependent!
In Intel’s testing, they noticed that there was contention over a certain lock in InnoDB. In most applications that scale to running multiple threads in parallel, there are points that are going to need to be serialised. This is so that the same bit of memory isn’t read or written at the same time, or to make sure things are written to disk in the correct order and not two different things over the top of each other.
When there are lots of threads trying to access one code path, they need to get queued up, and there are many different ways of doing this. Most of them involve various locking algorithms so that only one thread can gain access at a time. The method MariaDB Server used for part of the InnoDB transaction log was working great for the older platforms, but for newer platforms, such as Emerald Rapids, contention could be seen. Unfortunately, the fix to make this fast for Emerald Rapids, could also make things slower for older platforms.
The solution: innodb_log_spin_wait_delay
With Intel providing pointers to the issues, Marko came up with a new InnoDB option called “innodb_log_spin_wait_delay”. This sets a delay before each thread tries to gain the lock. On older Intel architectures such as Haswell, setting this variable causes things to run a little slower, but with the newer and faster modern architectures the delay becomes a lower cost. This is relatively similar to the “Thundering herd problem“, and needless to say, multi-threaded programming can be a complex topic.
Delivered as a feature in 10.11 onwards
The new “innodb_log_spin_wait_delay” variable is in MariaDB Server 10.11.8, 11.0.6, 11.1.5, 11.2.4 and 11.4.2. It can be set using SET GLOBAL so that it can be changed on-the-fly to test with your configuration.
The net result is, with a 64-core Emerald Rapids CPU, you can achieve more than 1 million NOPM (New Orders Per Minute) in the HammerDB TPROC-C benchmark. That equates to 2.3 million stored procedure transactions per minute in that test.
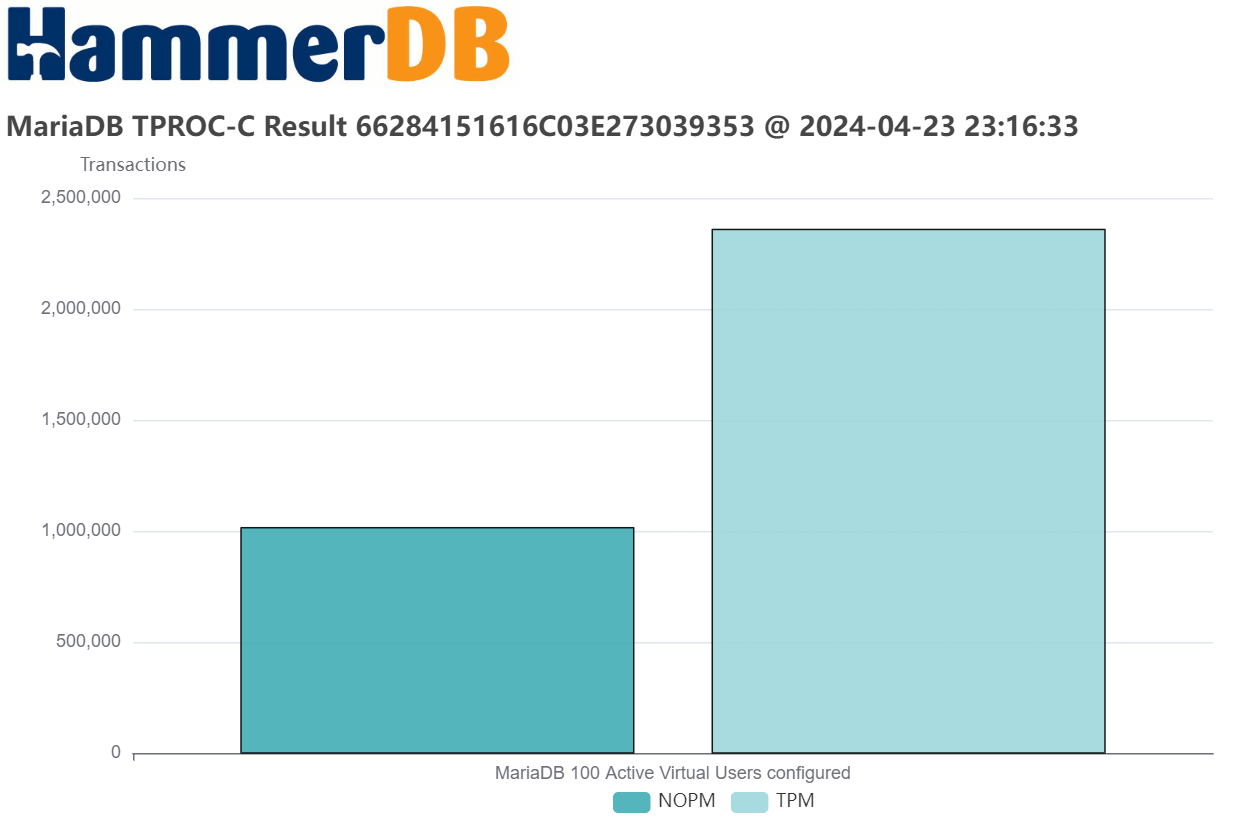
And this is the test running over several minutes to show the consistency.

The verdict from HammerDB: 10% faster performance
Whilst I don’t have exact numbers, this fix gave us something along the lines of a 10% performance increase on this platform.
I had a chat to Marko about this, and he said another thing they have recently helped us with is improving the performance of the CRC-32 algorithms used for MDEV-33817 (Implement AVX512BW and VPCLMULQDQ based CRC-32 algorithms). Intel pointed him to some reference code on a newer algorithm that uses modern vector instructions implemented in more recent architectures. Marko said this led to a 3x performance improvement in CRC-32C calculation, and whilst this isn’t an expensive operation to begin with, every little bit helps to improve the performance of your database.
Whilst our own testing would have likely found similar things over time, Marko said that the people who know their own architecture inside and out are far more likely to find these things quicker.
This is why, as I’ve mentioned in the past, we value the partnership we have with Intel. Even though they do not contribute a lot of direct code, the feedback they give us is just as valuable, if not more so.